Forvia

Illustration
forvia.com
Forvia, créé en 2022 par le rapprochement de deux leaders technologiques de l'automobile, Faurecia (fondé en 1914) et Hella (fondé en 1899), est aujourd'hui classé 7ᵉ équipementier automobile mondial. À ce jour, il est estimé que le groupe équipe 1 véhicule sur 2 dans le monde avec ses technologies et emploie plus de 150 000 collaborateurs à l'échelle mondiale. Forvia est un leader dans les domaines de l'intérieur de véhicule, de l'électronique embarquée, des systèmes de contrôle des émissions et des technologies de mobilité durable.
Au sein du groupe, le département GIT (Global Information Technology) est chargé de concevoir, développer et maintenir les solutions numériques globales. J'ai intégré l'équipe CCS (Collaborative and Cloud Services), spécialisée dans les services cloud collaboratifs et les solutions d'intelligence artificielle générative, en s'appuyant notamment sur Microsoft Azure et des technologies innovantes. Ma mission s'est déroulée sur le site de Seloncourt, puis Bavans, où j'ai été pleinement impliqué dans plusieurs projets structurants.
Dans ce contexte, j'ai eu l'opportunité de développer mes compétences à travers des projets concrets : l'automatisation de la fusion de données pour le département FIS (Faurecia Interior Systems) (compilation et traitement automatisé de données marketing), le développement du portail SQP (Supplier Quality Portal) dans un contexte international, ainsi que l'automatisation des processus de déploiement. Ces expériences m'ont également permis de contribuer aux initiatives du groupe autour de l'intelligence artificielle générative (GenAI).
À travers ce portfolio et mes projets, je tenterai ainsi plus particulièrement de démontrer ma maîtrise de deux compétences académatiques, à savoir : compétence 1 "Réaliser un développement d'application" ainsi que de la compétence 6 "Collaborer au sein d'une équipe informatique", en m'appuyant sur les projets réalisés et les défis techniques relevés au cours de cette année.
La "Base de données" FIS

Logiciel tableur Excel
microsoft.com
Présentation
Le département FIS
Faurecia Interior Systems - Division spécialisée dans les systèmes d'intérieur automobile
(Faurecia Interior Systems) s'appuyait depuis plus de dix ans sur un fichier Excel regroupant plus de 10 000 lignes et 400 colonnes de données stratégiques. Ce document, considéré en interne comme une véritable "base de données", servait de référence pour le suivi des programmes automobiles mondiaux.
Deux à trois fois par an, ce fichier devait être mis à jour à partir de volumes de production fournis dans des fichiers Excel externes. Réalisée manuellement par une personne dédiée, cette opération mobilisait 3 à 4 semaines de travail à chaque mise à jour, avec un risque d'erreurs important. L'objectif était d'automatiser partiellement ce processus pour réduire significativement la durée des mises à jour tout en améliorant la fiabilité des données.
La table ci-dessous les correspondances attendues entre le fichier GR (Group, contenant les nouvelles données à intégrer) et le fichier FIS (la « base de données »). Chaque ligne définit une relation entre deux colonnes, c’est-à-dire une donnée à transférer du fichier source vers le fichier cible lors de la mise à jour.
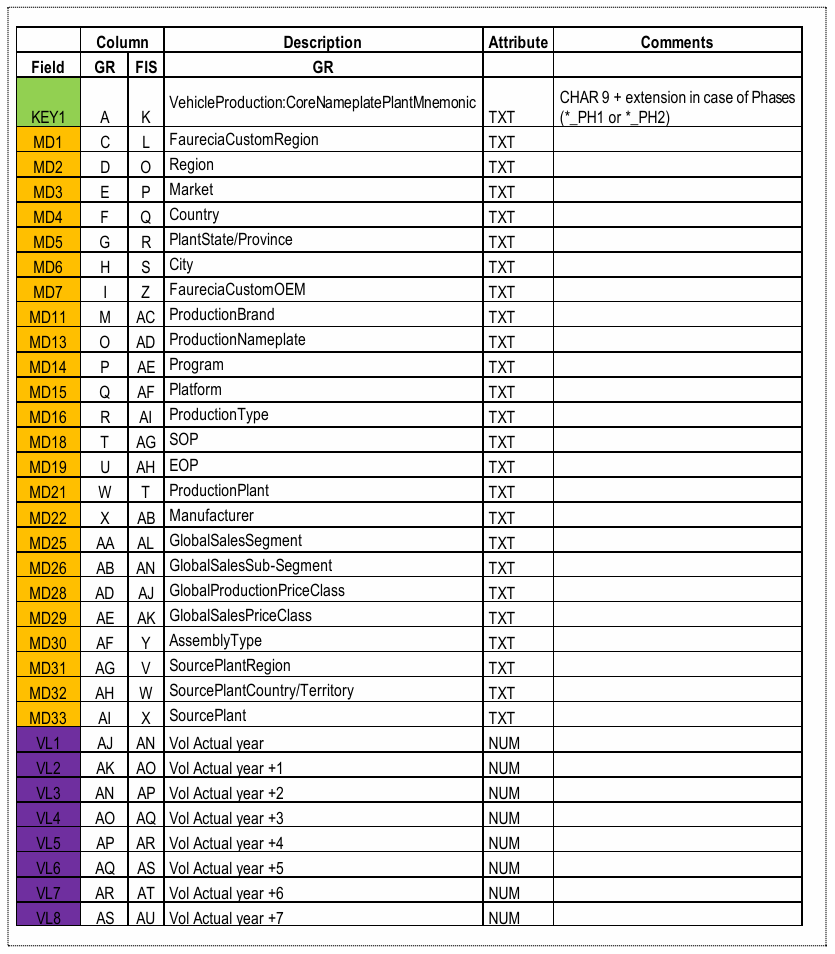
Illustration 1 — Table de correspondances entre colonnes des fichiers GR et FIS
La Mission
La mission a été cadrée par un Request for Change
RFC - Document formel décrivant un besoin de modification dans un système informatique
(RFC) décrivant précisément le problème métier et fournissant un pseudo-code détaillant les règles de comparaison, les cas de création et de mise à jour, ainsi que les statuts attendus.

Illustration 2 — Spécifications fonctionnels issus du fichier FCS
Réalisation
Le développement s'est structuré autour de plusieurs étapes clés, en posant d'abord les choix architecturaux généraux avant d'itérer fonctionnalité par fonctionnalité.
Architecture cible et flux envisagés
L'application était destinée à être hébergée sur Azure
Plateforme cloud de Microsoft offrant des services d'hébergement et de calcul
. Dans l'idée, l'utilisateur aurait déposé deux fichiers via une interface web. Chaque fichier aurait été stocké dans un conteneur Blob
Service de stockage Azure pour fichiers volumineux (Binary Large Object)
distinct. Après pré-contrôles, la fusion s'exécuterait automatiquement, et le fichier de sortie serait généré dans un Blob de résultat puis proposé au téléchargement. Ainsi, j'ai opté pour une approche qui minimise les paramètres côté interface utilisateur : le programme déduit automatiquement le maximum d'informations (mapping, en-têtes, types de données), avec la possibilité de persister un fichier JSON
Format de données léger pour échanger des informations structurées
de configuration pour les cas complexes.
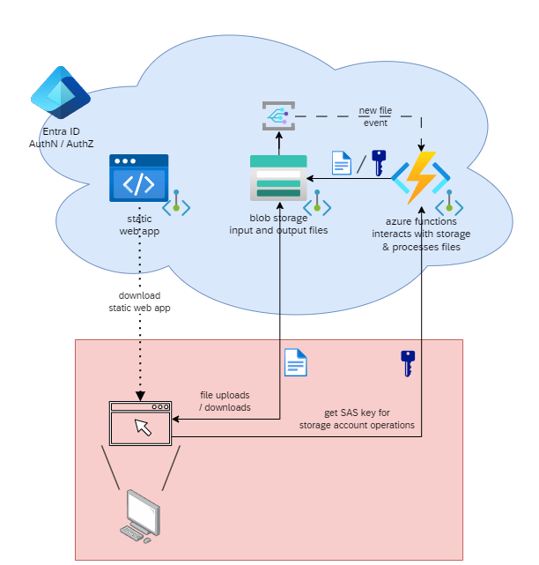
Trace 1 — Proposition d'architecture réalisé par Frédéric (mon maître d'alternance)
Pour cette première version, j'ai opté pour une application console structurée de manière modulaire : Models (structures de données), Services (lecture, mapping, fusion, stylisation), Program.cs (orchestration du processus global). Cette séparation facilite l'ajout de nouvelles fonctionnalités sans impacter l'existant et ouvre la voie à une future migration vers Azure (Functions Service Azure pour exécuter du code sans gérer de serveur (serverless) ou WebApp Service Azure pour héberger des applications web complètes ) en réutilisant les services développés.
Concrètement, les modèles sont utilisés par des services spécialisés : le LoaderService gère la lecture des fichiers, le ExcelService déduit les correspondances entre colonnes, le ExcelMergeRulesService applique les règles de fusion selon le RFC, et le OutFileService gère l'écriture des fichiers modifiés. Le fichier Program.cs orchestre l'ensemble en suivant une séquence claire : chargement des fichiers, génération du mapping, fusion des données, application du style, sauvegarde du résultat.
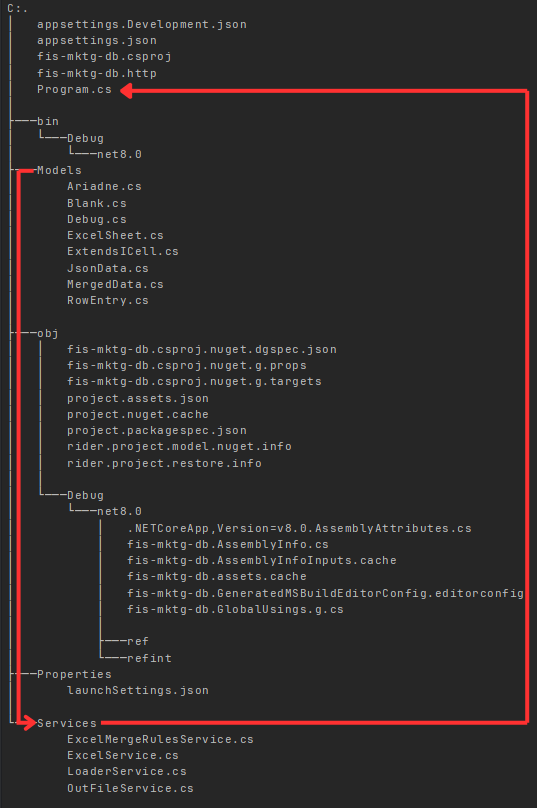
Trace 2 — Organisation du code
1. Conformité au pseudo-code du RFC
J'ai d'abord transposé fidèlement les règles métier définies : comparaison systématique des lignes entre les deux fichiers, création d'une nouvelle entrée si aucune correspondance n'est trouvée, mise à jour dans le cas contraire. Le système attribue automatiquement un statut ("OK", "OK/Manual", "To be checked", "NEW") avec mise en forme colorée correspondante pour faciliter l'identification visuelle des différents cas de traitement.
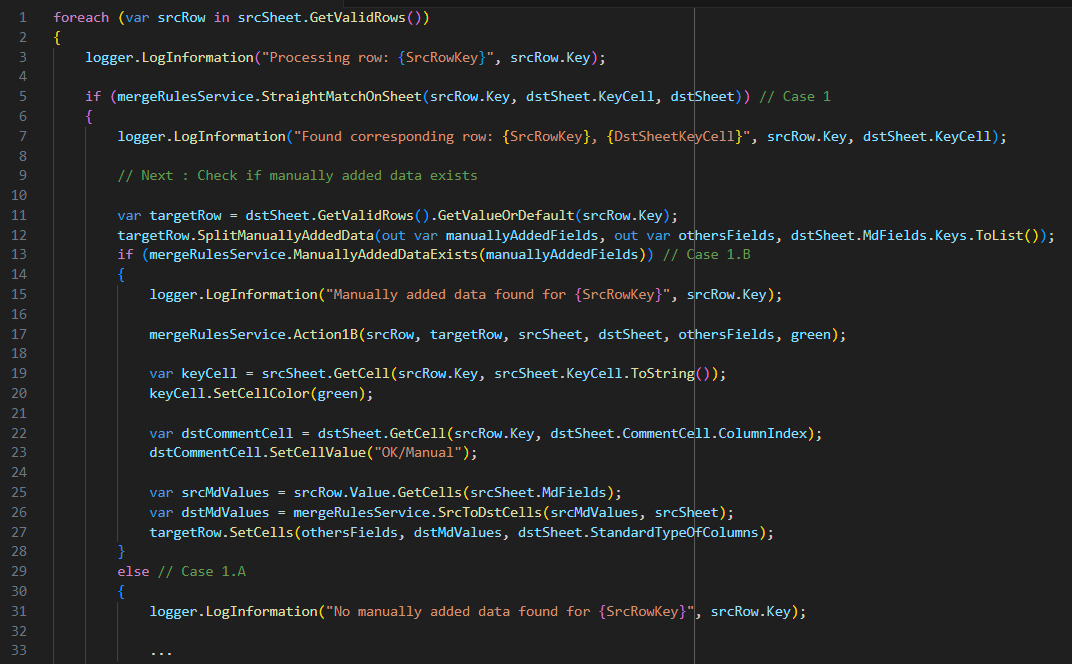
Trace 3 — Extrait du code appliquant les règles d'automatisation
2. Génération automatique du mapping
Pour éviter les paramètres de configuration fragiles, j'ai implémenté un système de détection automatique. La détection de l'en-tête (labels) s'effectue par identification de la ligne de labels via analyse de la densité textuelle (ligne contenant le plus de chaînes de caractères). L'appariement des colonnes se fait par correspondance directe lorsque les labels coïncident parfaitement, avec un fallback
Solution de repli utilisée quand la méthode principale échoue
intelligent : en cas d'échec, le système analyse la cellule supérieure (particulièrement utile pour les en-têtes comme "Vol. 2024").
Le mapping généré au format JSON peut être édité manuellement pour affiner les correspondances si nécessaire, offrant ainsi une flexibilité entre automatisation et contrôle utilisateur.
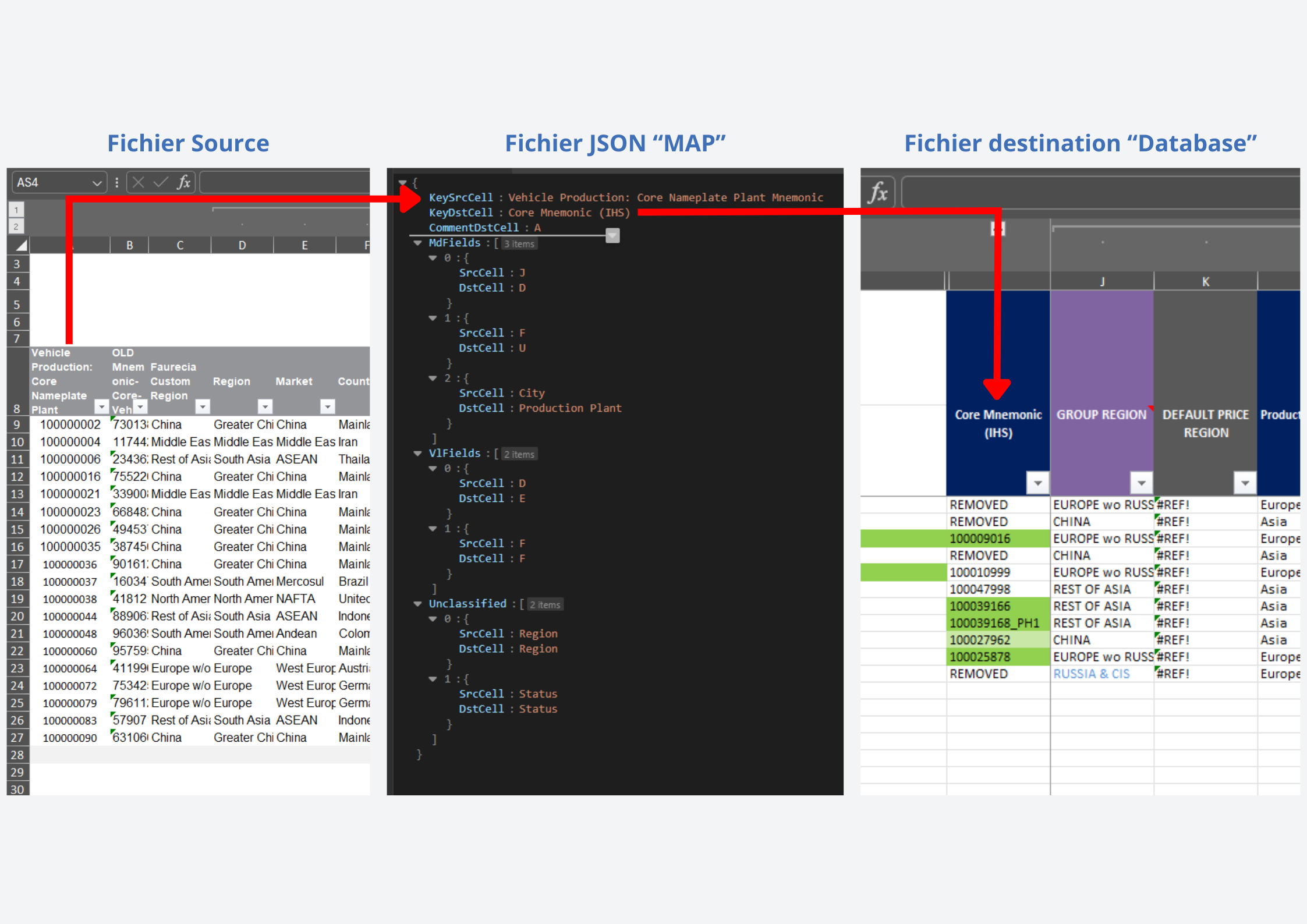
Trace 4 — Le fichier JSON permet d'établir les correspondances entre les colonnes des deux fichiers
3. Gestion des types et conservation du style
Pour garantir la cohérence et éviter les retouches manuelles post-traitement, j'ai mis en place un système de conversion automatique et de préservation du style. Chaque valeur insérée est automatiquement convertie selon le type dominant de la colonne cible (texte, nombre, date), évitant les incohérences de format. Parallèlement, le système reproduit fidèlement les styles existants (colonnes colorées, formatage spécifique) pour maintenir la lisibilité du document final et réduire au maximum le nombre de correction manuel à apporter.
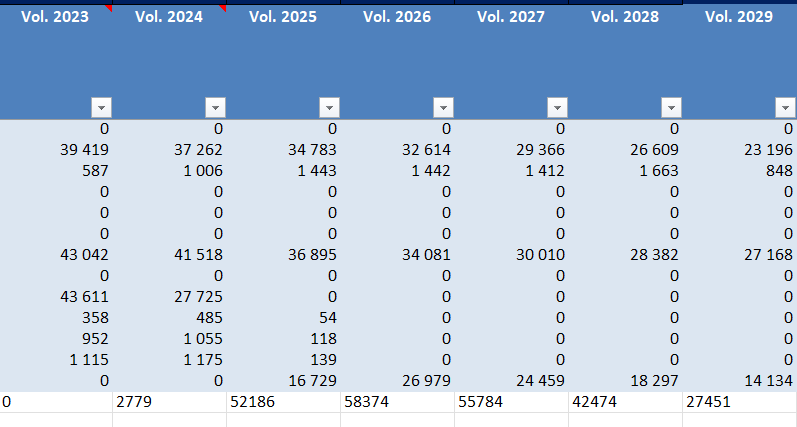
Illustration 3 — Voici ce qu'il se passe si on ne tient pas compte du style et du format des données quand on rajoute une nouvelle ligne. Il n'y a pas de couleur, et les chiffres sont sous format texte !
Supplier Quality Portal
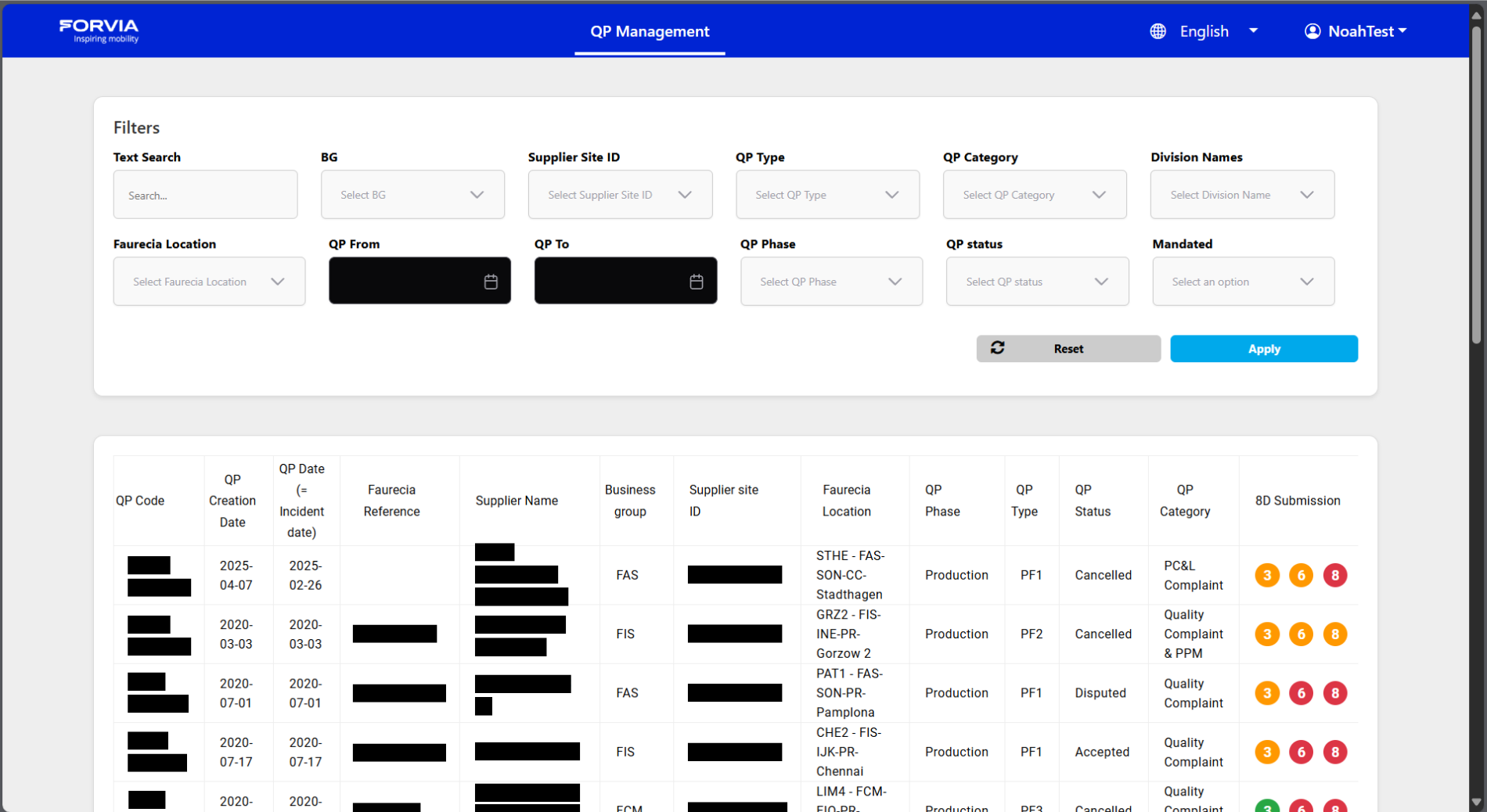
Le Supplier Quality Portal / QP Management
forvia.com
Présentation
Le projet SQP
Supplier Quality Portal - Portail de gestion de la qualité fournisseurs
(Supplier Quality Portal) s'inscrivait dans un contexte stratégique majeur pour Forvia : remplacer l'ancienne application GPS
Global Purchasing System - Ancien système de gestion des achats et non-conformités
(Global Purchasing System), utilisée pour gérer les non-conformités fournisseurs selon la méthodologie 8D
Méthode de résolution de problèmes en 8 étapes utilisée dans les entreprises pour la résolution de problèmes qualité
. Les fournisseurs y soumettaient leurs documents correctifs, puis les données étaient transférées automatiquement vers QSS
Quality Steering System - Système interne de pilotage qualité de Forvia
(Quality Steering System) pour traitement interne.
La licence GPS représentait un coût annuel d'environ 200 000 €, avec une échéance critique en juillet 2025. L'enjeu était clair : si le nouveau portail n'était pas livré à temps, l'entreprise devait renouveler une licence particulièrement coûteuse. Le projet SQP combinait donc des contraintes de délai serrées avec des enjeux financiers et de continuité d'activité importants.
La Mission
Dans ce projet, ma mission s'est concentrée sur la conception et le développement du système de gestion des utilisateurs et des groupes dans SQP. Le système devait traiter des fichiers JSON
Format de données structuré permettant d'échanger des informations entre systèmes
décrivant différentes actions : création ou suppression de comptes, mise à jour des informations utilisateurs, gestion des liens entre contacts et groupes, ainsi que l'envoi automatique de notifications par email.
L'objectif était de concevoir une logique robuste permettant de lire ces instructions de manière fiable, de les exécuter sans erreur et de notifier automatiquement les utilisateurs concernés par les modifications apportées à leurs comptes.
L'architecture proposée ci-dessous illustre dans les grandes lignes le fonctionnement envisagé. Dans celle-ci, seule la création des comptes avec Entra, visible dans la partie centrale, était sous ma responsabilité, le reste, tel que la partie Frontend ou l'import des fichiers QP a été assigné à d'autres membres de l'équipe.
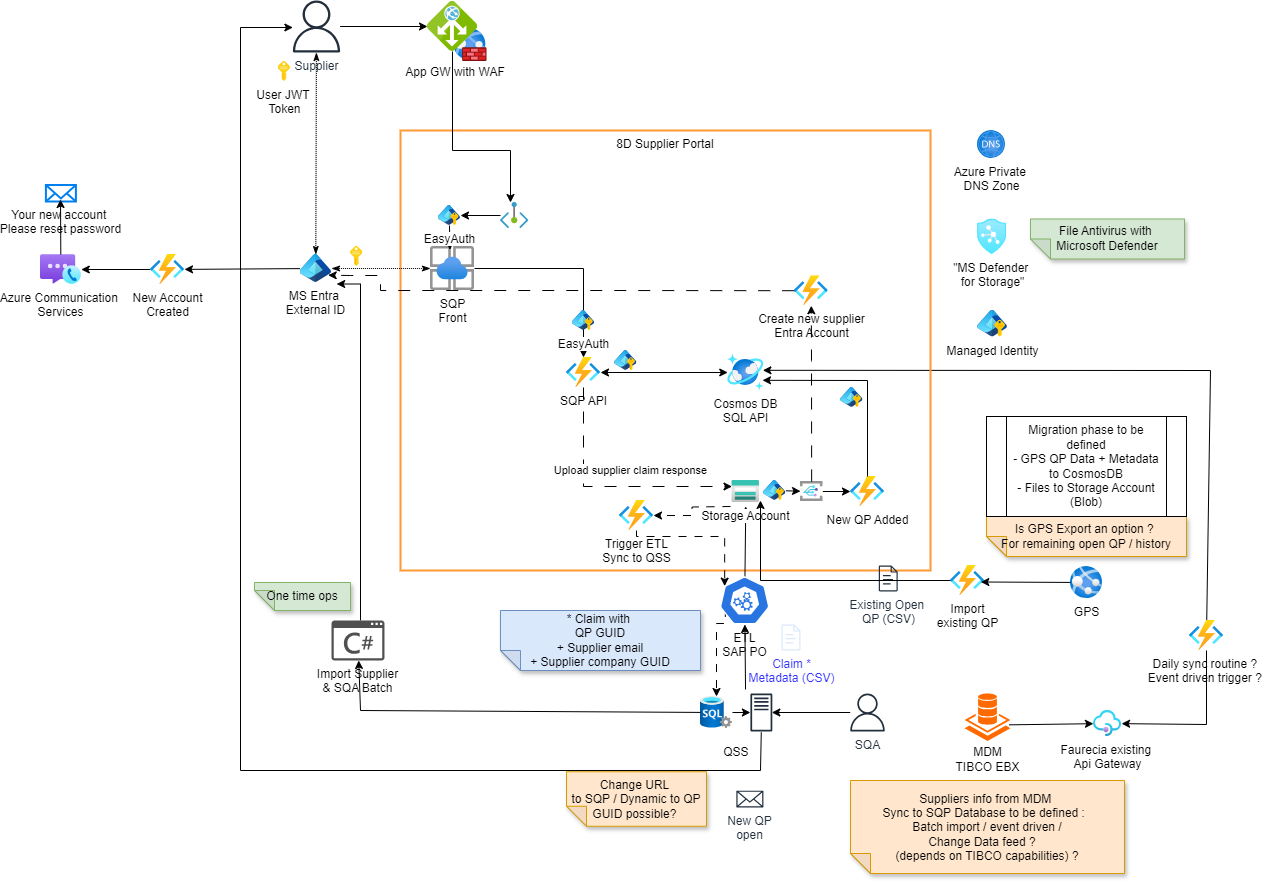
Trace 5 — Proposition d'architecture réalisé par Frédéric (mon maître d'alternance)
Réalisation
Le développement du système s'est structuré autour d'une architecture cloud native, tirant parti des services Azure pour assurer performance et scalabilité.
Architecture générale
Pour traiter efficacement les instructions, nous avons mis en place une Azure Queue
Service de file d'attente Azure pour traiter des messages de manière asynchrone
. Chaque message JSON était déposé dans cette file, puis consommé par une Azure Function
Service serverless Azure permettant d'exécuter du code sans gérer d'infrastructure
dédiée. La logique centrale reposait sur un système de routage par switch, faisant office de hub de distribution selon le type d'action : création de compte, suppression, mise à jour, ou modification des liens entre utilisateurs et groupes.
Tout au long de ce processus, le statut de la requête est mis à jour dans une Azure Table
Banque de données NoSQL Azure pour stocker des informations structurées
dédiée, permettant un suivi précis de chaque opération. L'application qui a envoyé le message peut ainsi consulter l'état d'avancement en temps réel par un système dit de
"polling".
Technique consistant à interroger périodiquement un service pour obtenir des mises à jour
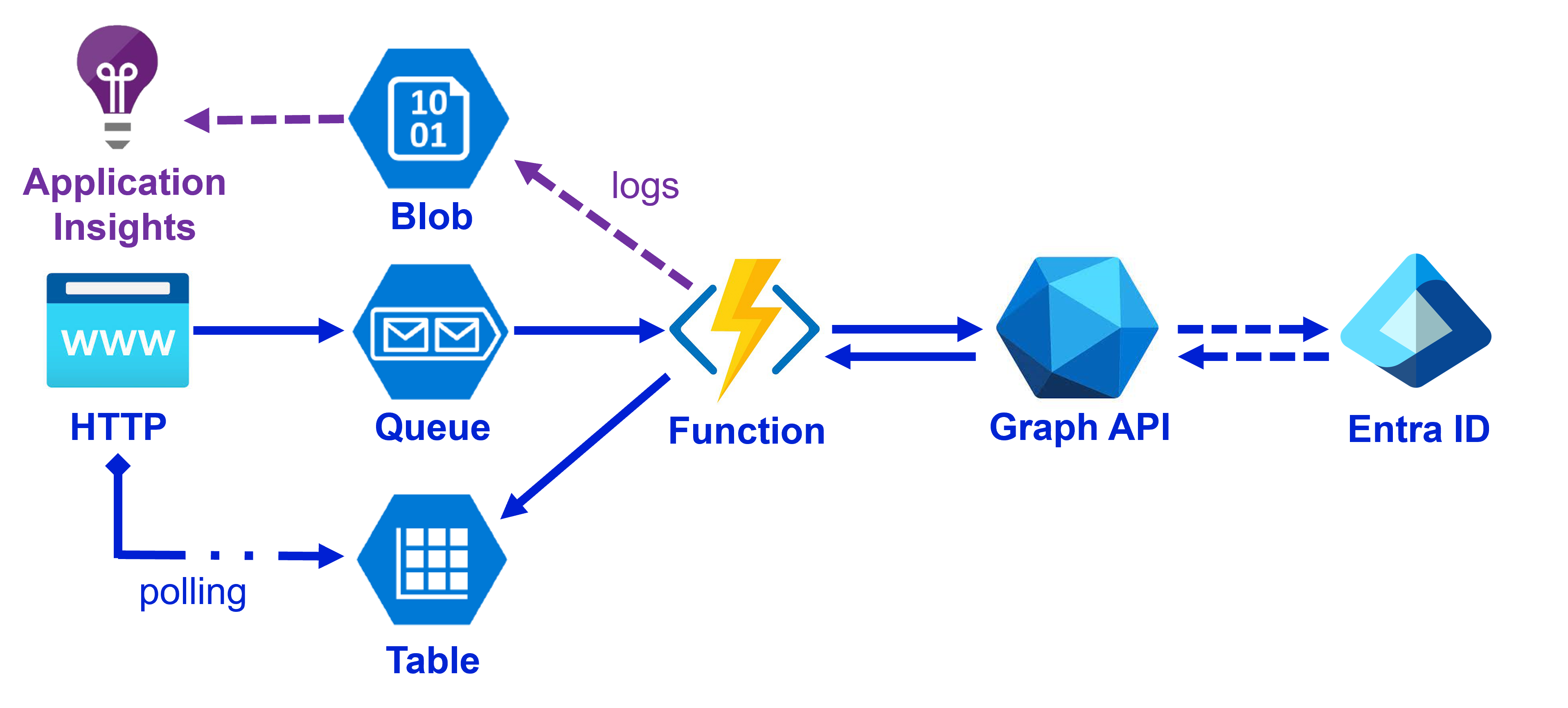
Trace 6 — Schéma de la partie "Création des comptes" réalisé
1. Gestion des cas d'usage métier
Le système intègre plusieurs fonctionnalités essentielles pour répondre aux besoins opérationnels. L'envoi automatique d'emails s'effectue dès qu'un compte est créé ou modifié pour la première fois, garantissant une information immédiate des utilisateurs concernés.
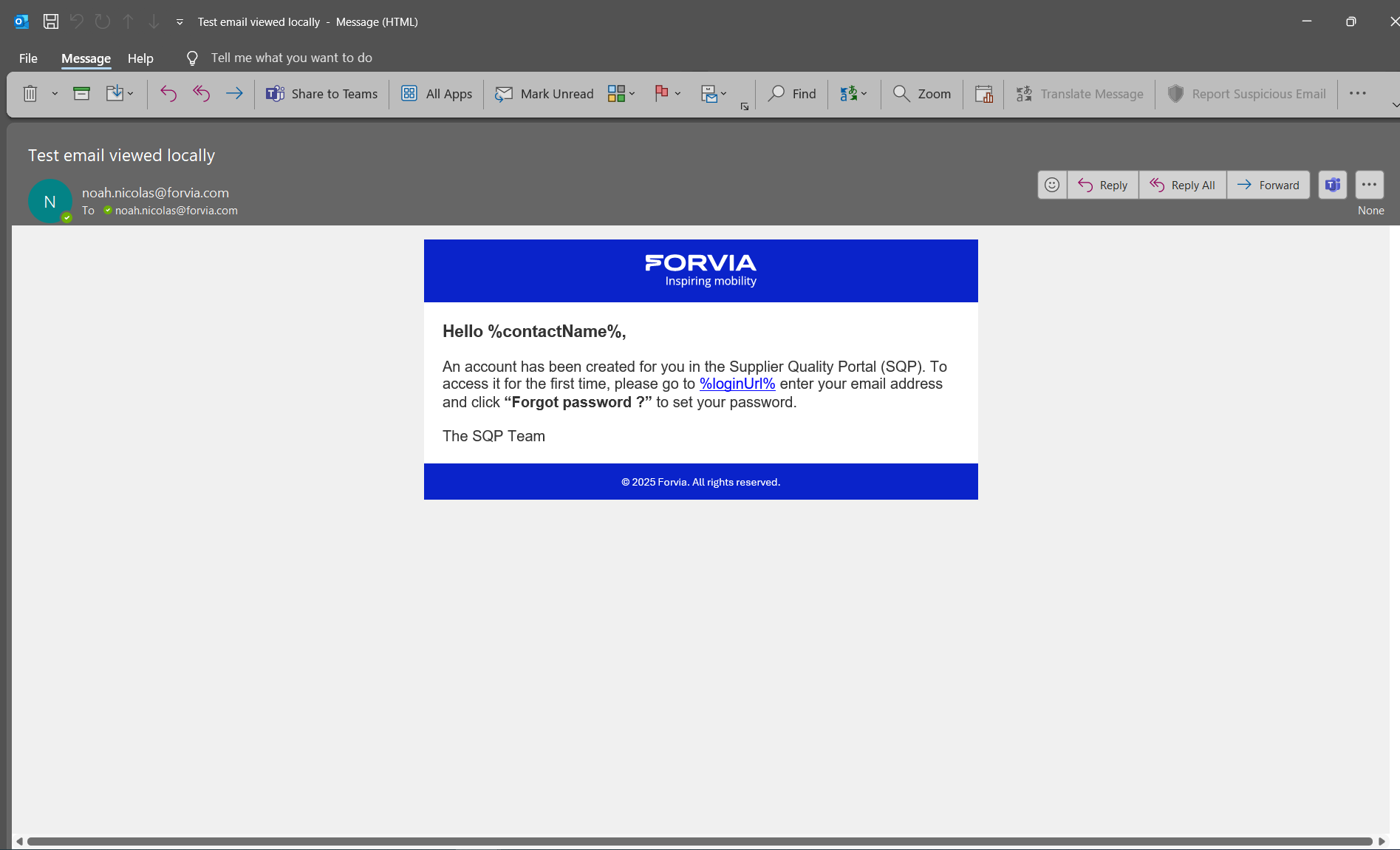
Trace 7 — Test lors du maquettage de la notification email
Pour gérer l'asynchronisme inherent aux messages de queue, j'ai également adapté le système afin d'également pouvoir regrouper plusieurs instructions dans un seul JSON sous forme de liste d'actions. Cette approche garantit la cohérence des opérations lorsque cela est nécessaire.

Trace 8 — Exemple de fichier Json avec multiples instructions (lignes 3-26 AddSupplierContact puis lignes 27-39 RemoveSupplierContact)
2. Déploiement et pipelines DevOps
Le projet suivait un cycle complet DevOps
Approche combinant développement et opérations pour automatiser les processus
via Azure DevOps
Plateforme Microsoft pour la gestion du cycle de vie des applications
. L'utilisation de feature branches
Branches Git dédiées au développement de nouvelles fonctionnalités
permettait d'isoler les développements, tandis que la validation par pull request
Demande de fusion de code permettant la revue collaborative
et review garantissait la qualité du code. Le déploiement automatique en environnement de développement s'effectuait après merge, avec une promotion progressive en Preproduction puis Production selon les règles définies.
Cette organisation garantissait à la fois la fluidité des tests et la sécurité des mises en production, éléments critiques compte tenu des enjeux temporels du projet.
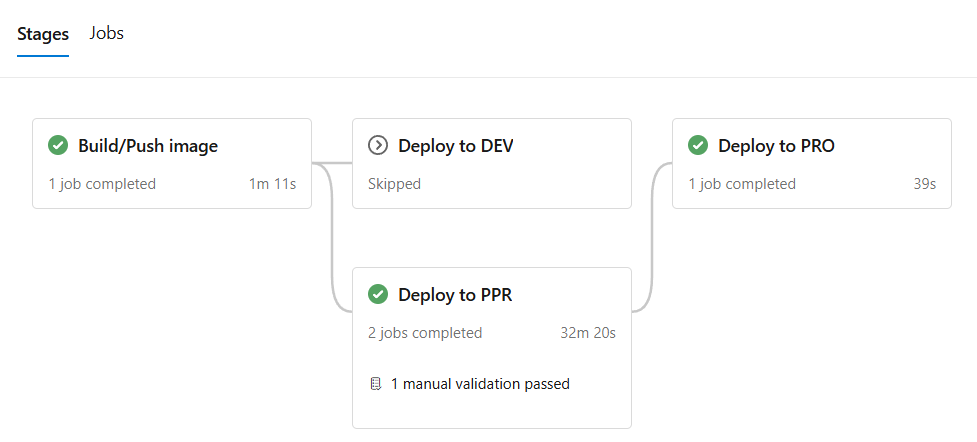
Trace 9 — Cas de figure : déploiement du code en production avec Azure DevOps
3. Infrastructure as Code
L'infrastructure cloud est entièrement décrite en Terraform
Outil d'Infrastructure as Code permettant de gérer l'infrastructure par du code
, garantissant reproductibilité et traçabilité des déploiements. Sur ce projet cependant, je n'ai effectué que des modifications mineurs. Un exemple concret concernait la configuration du Blob Storage
Service de stockage Azure pour fichiers volumineux
: les fichiers temporaires générés étaient automatiquement supprimés après un délai défini, permettant d'éviter toute surcharge inutile et de maîtriser les coûts d'infrastructure.
Cette approche Infrastructure as Code
Méthode de gestion de l'infrastructure par des fichiers de configuration versionnés
facilitait également la maintenance et les évolutions ultérieures de l'architecture.
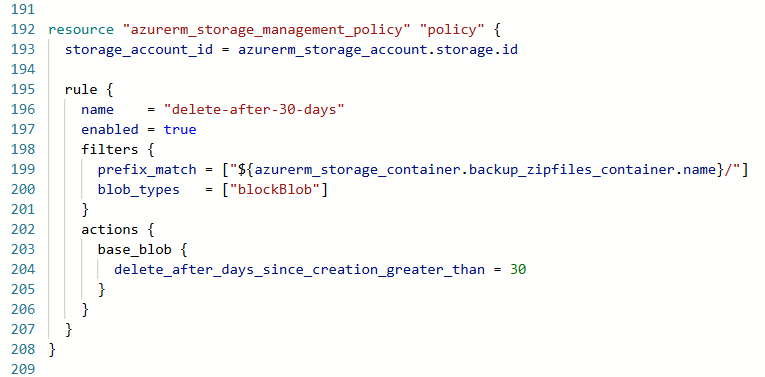
Trace 10 — Example d'utilisation de Terraform : Création d'une règle de suppression de fichier appliqué à un Blob Storage défini plus haut (non-visible ici)
4. Documentation et transfert de connaissances
L'ensemble du projet a été documenté dans un wiki interne structuré, incluant les procédures de déploiement, les formats attendus (JSON, CSV), ainsi qu'une description détaillée du workflow de traitement. Cette documentation centralisée permettait à chaque membre de l'équipe, y compris les nouveaux arrivants, de disposer d'une référence claire et partagée.
L'approche documentaire adoptée facilitait la maintenance future et le transfert de connaissances, aspects essentiels dans un contexte de collaboration internationale.
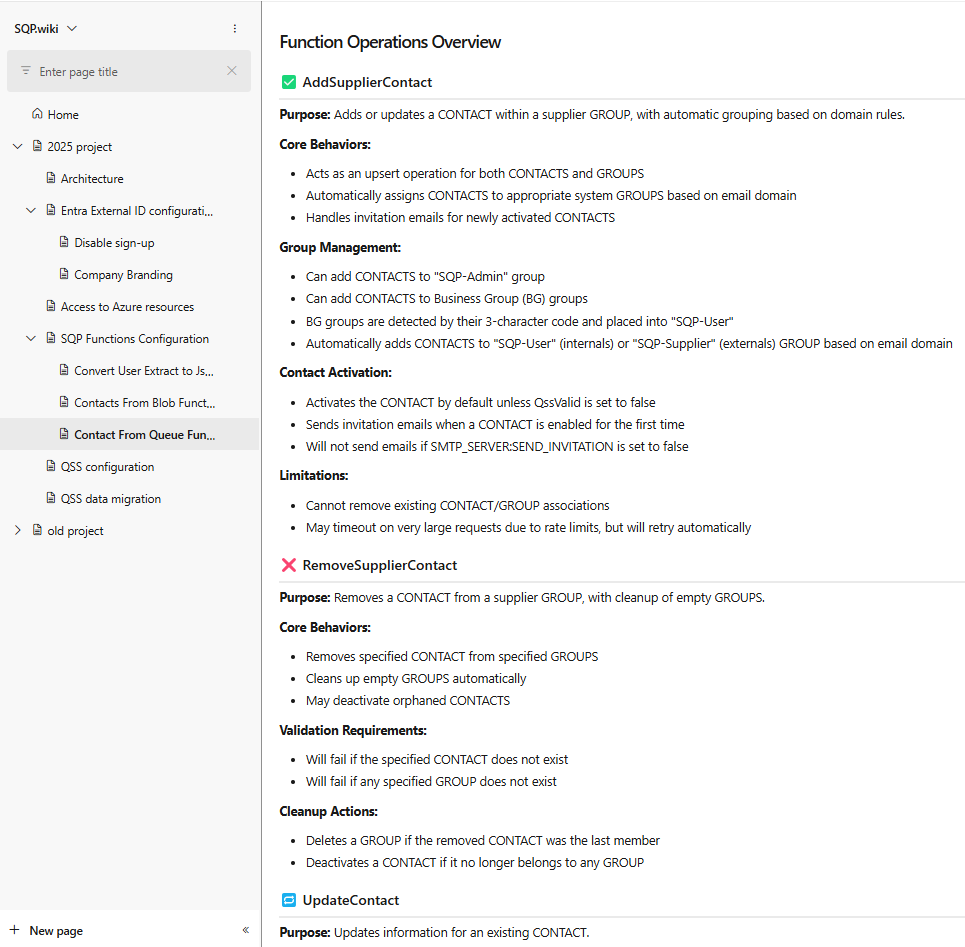
Trace 11 — Extrait d'une page du wiki du projet sur Azure DevOps
5. Collaboration internationale
Le développement de SQP s'est effectué en étroite collaboration avec l'équipe CCS française et l'équipe tunisienne. Des réunions quotidiennes permettaient de faire le point sur l'avancement, de répartir efficacement les tâches et de discuter collectivement des problèmes rencontrés.
Cette organisation favorisait une communication fluide et une coordination efficace malgré la distance géographique. Elle m'a permis de développer mes compétences en collaboration d'équipe internationale tout en maintenant une vision claire de la progression collective du projet.
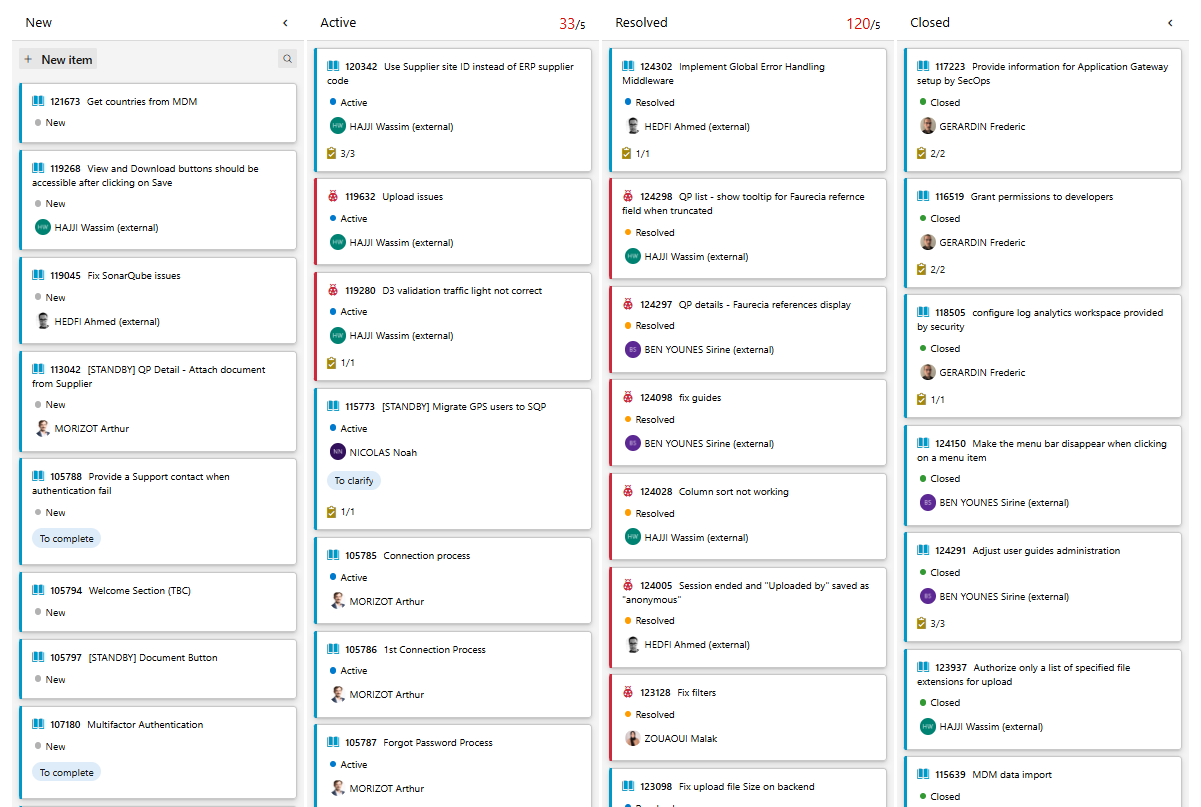
Trace 12 — Extrait du tableau des tâches sur le projet SQP (Azure DevOps)
Académique | Compétences travaillées
Compétence 2 — Optimiser des applications
Dans le projet SQP, l'utilisation de Microsoft Graph API
API Microsoft permettant d'accéder aux services Office 365 et Azure Active Directory
impose des contraintes de quotas
Limites sur le nombre de requêtes autorisées par période de temps
et de throttling
Mécanisme de limitation automatique des requêtes en cas de surcharge
. En fonctionnement courant, l'utilisation d'une Queue suffit (faible volume, retry simple). Cependant, pour la migration massive lors de la reprise des comptes existants, j'ai anticipé le goulot d'étranglement en limitant la concurrence par une SemaphoreSlim(100)
Mécanisme de limitation du nombre d'opérations simultanées à 100
et en implémentant un backoff logarithmique
Stratégie d'attente progressive basée sur une fonction logarithmique
(délai modulé par `Math.Log`, borné), permettant de lisser les rafales d'appels sans perdre de débit sur les opérations rapides.
AC couverts : AC1 (anticiper les métriques de performance), AC2 (analyser et ajuster via logs et erreurs 429), AC3 (méthodes d'optimisation adaptées : sémaphore + backoff).
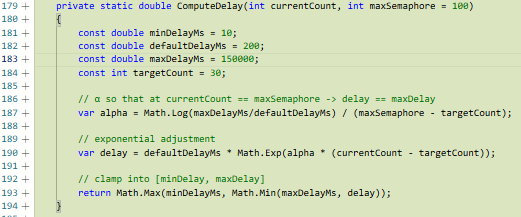
Illustration 4 — Extrait de code de la fonction du calcul de délai entre requêtes
Compétence 3 — Administrer des systèmes communicants
J'ai conçu et opéré des traitements serverless
Architecture sans serveur où le code s'exécute à la demande
avec Azure Functions (triggers HTTP et Queue) et Azure Storage (Queue + Blob), échangeant des JSON d'instructions pour la création, suppression, mise à jour et rattachements de groupes, ainsi que la génération automatique d'emails. Les déploiements s'effectuaient via Azure DevOps sur un pipeline structuré Dev → Preproduction → Production avec des services virtualisés.
Côté sécurité, j'ai, par exemple, durant mes tests, offusqué les adresses emails présentes dans les données de test. Cela a deux utilités, cela évite les accidents d'envoi de mails, et cela garantie que seul la personne qui a généré les données sait a quel compte correspond quelle adresse email offusqué grâce à une "map" générée à partir d'une "seed" (graine aléatoire). Cela est pratique afin d'identifier les erreurs créées par des comptes contenant des informations invalides ou mal formatés.
AC couverts : AC1 (application communicante), AC2 (services virtualisés), AC3 (sécurisation des échanges et des données).
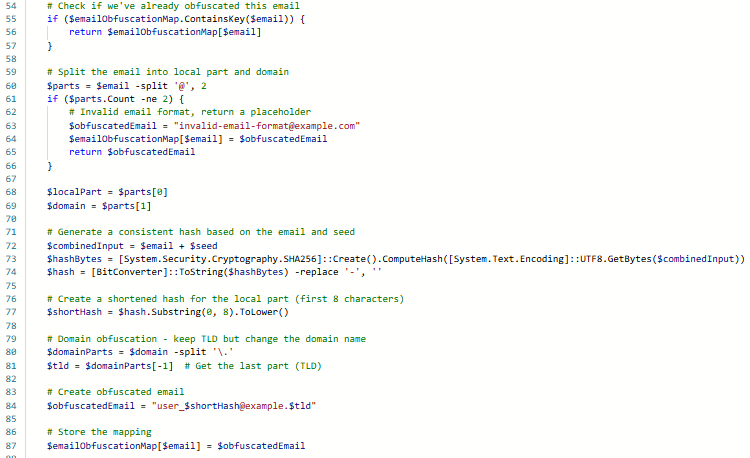
Illustration 5 — Extrait d'un script offusquant les adresses email des utilisateurs pour les tests
Compétence 4 — Gérer des données de l'information
Sur le projet FIS, j'ai structuré la manipulation des données Excel selon une logique proche du relationnel : détection automatique de l'en-tête, mapping JSON des colonnes, normalisation des types (texte, nombre, date) et conservation des styles pour restituer un fichier exploitable. Sur SQP, j'ai également manipulé des formats JSON, CSV et gérer leur conversion sous modèles C#.
AC couverts : AC1 (préparer un modèle exploitable), AC3 (restitution exploitable), AC4 (données hétérogènes).

Illustration 6 — Modèle pour la réception des messages JSON de QSS
Compétence 5 — Conduire un projet
Dans le cadre des me différents projets, je me suis inséré dans un processus déjà défini par d'autres personnes ou équipes métiers et chefs de projet. J’ai dû comprendre le workflow général et situer ma partie (gestion des utilisateurs et groupes). Je n’ai pas été à l’origine de la formalisation des besoins dans leur grande majorité, mais j'ai quand même pu fournir mon aide sur certain détails tel que la définition des formats d'échanges JSON (SQP). J’ai également interprété le RFC fourni (pseudo-code, règles de gestion) pour en tirer des contraintes techniques applicables dans le code (statuts, conditions de création/mise à jour) (Base de données FIS).
Je n’ai pas non plus défini la démarche de suivi ni évalué la faisabilité du projet. En revanche, j’ai participé au suivi déjà en place : daily meetings, revue de tâches, branches de fonctionnalités, pull requests et pipelines Dev → Préprod → Prod.
AC couverts (participation seulement à): AC1 (processus métier), AC2 (formalisation des besoins), AC3 (critères de faisabilité), AC4 (démarche de suivi projet).
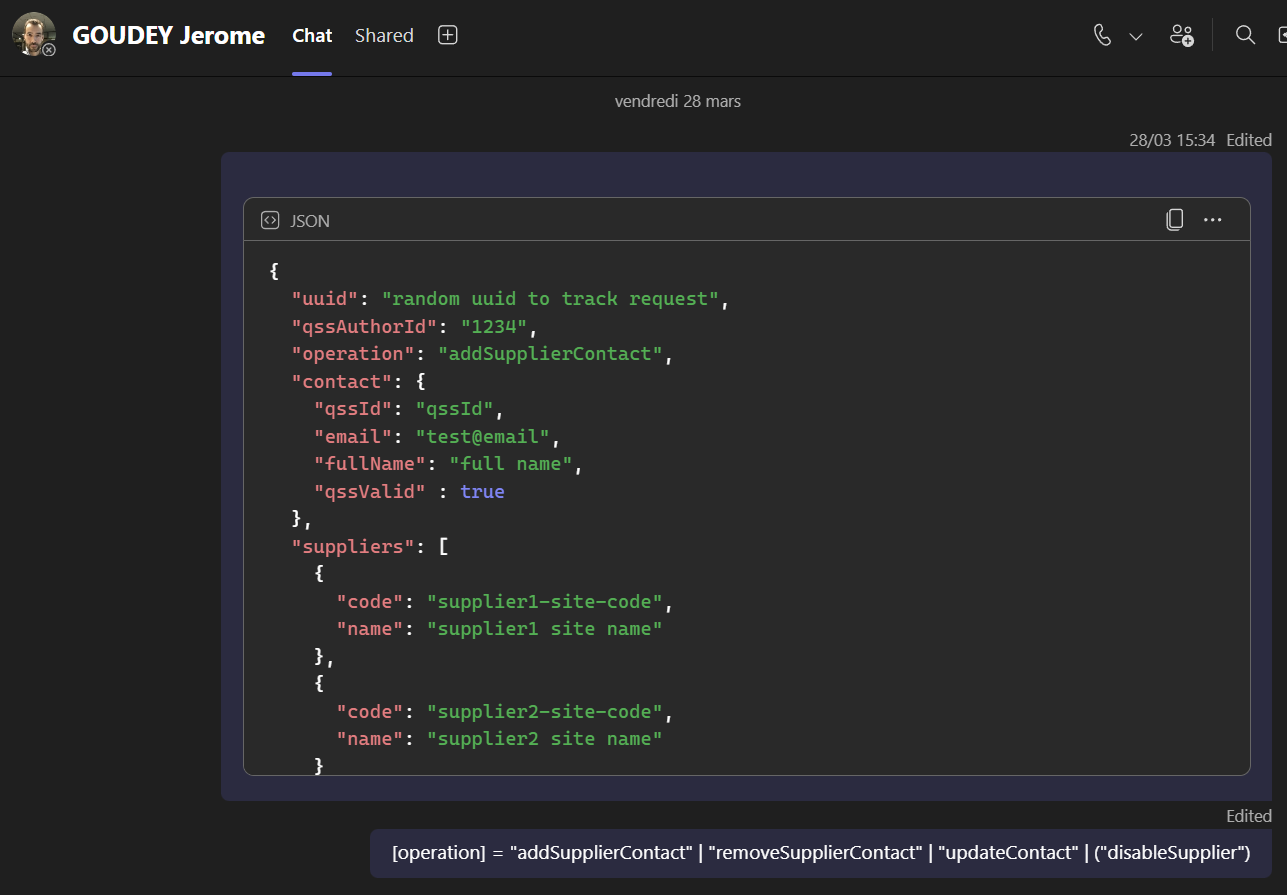
Illustration 7 — Définition du format de communication entre QSS et SQP avec Jérome, le chef de projet sur SQP
Compétence 6 — Collaborer au sein d'une équipe informatique
J'ai travaillé dans une équipe pluridisciplinaire répartie entre plusieurs sites (Bavans, Tunis, Inde), développant mes compétences en communication interculturelle et méthodes de travail collaboratives. J'ai participé aux échanges de veille technologique au sein de l'équipe CCS, notamment autour des solutions GenAI
Generative Artificial Intelligence - Intelligence artificielle générative
(Azure vs SAP), en relayant certaines conclusions techniques et en alimentant la réflexion collective.
Ma contribution à la documentation des développements (notamment SQP) dans un wiki accessible a facilité l'appropriation par d'autres développeurs et l'équipe support, préparant l'adoption des nouvelles solutions. J'ai assuré un reporting régulier lors des réunions quotidiennes et participé au suivi des tâches collectives via les outils collaboratifs, contribuant à la visibilité globale des projets.
AC couverts : AC1 (veille numérique partagée), AC2 (enjeux innovation GenAI), AC3 (préparation utilisateurs via documentation), AC4 (reporting et suivi projet).
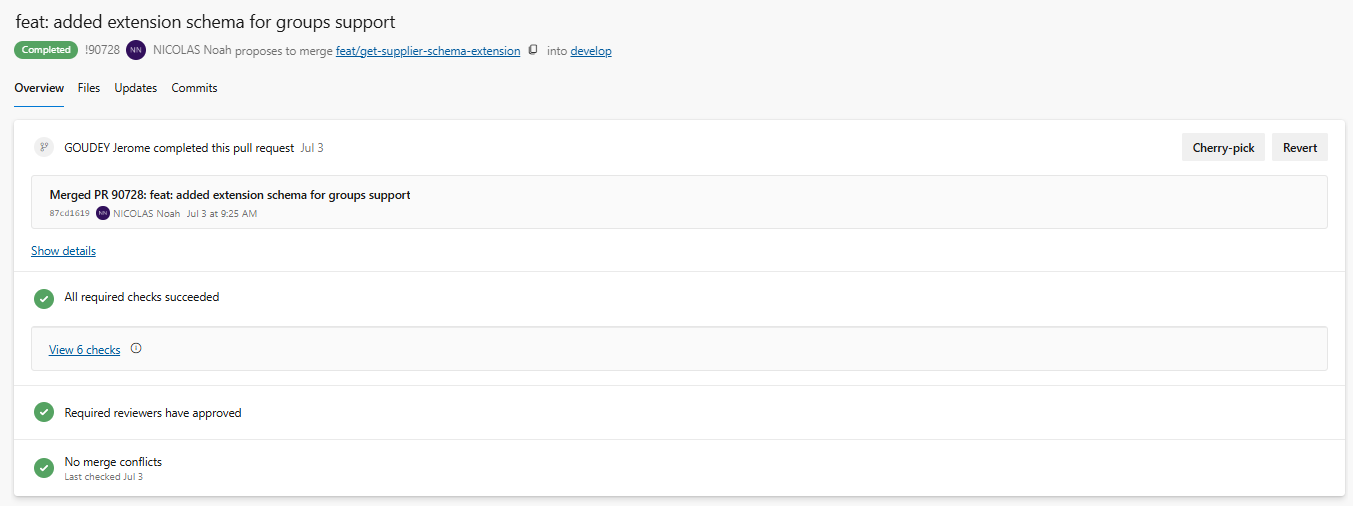
Illustration 8 — Pull Request validée après avoir passé la vérification automatique SonarQube et manuelle (review)